
En el blog de Last.fm anuncian la disponibilidad de su nueva API.
Introduce un protocolo de autenticación de usuarios, servicios de lectura y escritura para aplicaciones web, de escritorio y para dispositivos móviles. Incluye una API para etiquetado, de forma que se pueden obtener y aplicar etiquetas a la música desde cualquier plataforma.
Hay también nuevas APIs de búsqueda, de gestión de listas y de geo-posicionado para el contenido.
Link: www.last.fm/api
30 junio, 2008
Nueva API para Last.fm
26 junio, 2008
#
¿Por qué los navegadores aún no tienen indicadores de progreso cuando suben archivos?
Via SimonWillison.net.
Ni Firefox 3, ni IE 8, ni Opera 9.5, ni Safari 3.1.
Sin duda la pregunta del millón.
25 junio, 2008
Rendimiento excepcional
Exceptional performance es un equipo de la Red de Desarrollo de Yahoo! que evangeliza las mejores prácticas para mejorar la velocidad de respuesta de las aplicaciones web. Llevan a cabo investigación, herramientas de compilación, escriben artículos y blogs y dan conferencias. Sus mejores prácticas se centran en las reglas para conseguir sitios web que den respuestas rápidas. Las recomendaciones están organizadas en categorías: contenido, servidor, cookie, CSS, javascript, imágenes y móviles.
24 junio, 2008
Botón universal de edición
Al igual que cuando se accede a una web que incluye una fuente/feed RSS declarada de actualizaciones, se ve el icono 

El código para indicar que la página es editable y la URL de edición sería similar al siguiente (extraído de Wikipedia):
<link rel="alternate" type="application/x-wiki" title="Editar" href="http://en.wikipedia.org/w/index.php?title=HTML&action=edit" />
FUEL - Extensiones simples en Firefox 3
En 2007 John Resig (Mozilla foundation) creó junto con Mark Finkle una librería/API Javascript que facilitaba mucho la interacción con la interfície XPCom (XUL) del navegador Firefox. Dicha librería está disponible en la versión 3 de Firefox. Hoy, John Resig lo recuerda en su blog y da enlaces a la página principal, a la documentación y a una presentación de la tecnología. Ejemplos a continuación:
- Abrir Google.com en una nueva pestaña y activarla
Application.browser.open("http://google.com/").active = true; - Cerrar la pestaña actual del navegador
Application.browser.activeTab.close();
- Cerrar todas las pestañas que apunten a Google
Application.browser.tabs.forEach(function(tab){ if ( tab.url.match(/google/) ) tab.remove(); }); - Añadir un marcador a Mozilla.org
Application.bookmarks.add("Mozilla", "http://mozilla.org/"); - Eliminar todos los marcadores a Microsoft.com
Application.bookmarks.all.forEach(function(cur){ if ( cur.url.match(/microsoft.com/) ) cur.remove(); })
Addendum: En Sentido Web también lo explican.
23 junio, 2008
RescueTime

Llevo usando un par de meses RescueTime y ya lo consideró imprescindible. Se trata de una utilidad que analiza el tiempo que pasamos frente al teclado y es capaz de mostrar las aplicaciones y páginas en las que pasamos más tiempo. Es una herramienta ideal para controlar el tiempo que se pasa procrastinando (ya lo sé, suena fatal) en lugar de ser productivo.
Los resultados son muy clarificadores permitiendo mostrar toda clase de estadísticas, permitiendo etiquetar las aplicaciones o páginas para obtener directamente el tiempo dedicado a cada clase de tarea. También permite establecer alertas/objetivos que permiten indicar si queremos pasar más de x horas al día haciendo algo (productividad) o lo contrario (es decir, pasar menos de x horas perdiendo el tiempo en cosas que no son importantes). En resumen, imprescindible, aunque puede ser peligroso si se usa mal.
Security Compass Exploit-me
Exploit-Me es un conjunto de 3 extensiones para Firefox ligeras y fáciles de usar. Ver Presentación (PDF).
- XSS-Me es una herramienta para detectar vulnerabilidades de Cross-Site Scripting (o XSS)
- SQL Inject-Me detecta vulnerabilidades por inyección de código SQL. Un usuario malintencionado podría ver y eliminar registros o acceder con permisos de administrador.
- Access-Me permite detectar intentos de acceso a recursos a los que no se debe poder acceder a menos que se está autenticado correctamente.
20 junio, 2008
Editar o añadir puntos, líneas y polígonos con Google Maps
Google Maps ha ampliado su API para permitir utilizar sus mapas en aplicaciones web de forma que se permita que los visitantes puedan editar o añadir los elementos básicos que ya están disponibles en Mis Mapas: Puntos, líneas, o polígonos. De esa forma se facilita la utilización de la herramienta de Google para la introducción de información geográfica. Ejemplo:
Via Programa con Google.
19 junio, 2008
joose: sistema de metaobjetos para Javascript
Via aNieto2k. Se trata de un sistema autocontenido de metaobjetos con soporte para clases, herencia, uniones, tratos, modificadores de método y mucho más.
Joose facilita enormemente la programación orientada a objetos (OOP) con Javascript, haciéndola declarativa y muy productiva. Joose es multi-paradigma. Soporta el estilo tradicional basado en prototipos y el propio basado en clases, a la vez que la herencia basada en clases y la extensión basada en roles.
En el siguiente ejemplo (te lo he copiado enterito, Andrés) se define de una forma muy muy sencilla:
//Declaración del módulo
Module("PointModule", function (m) {
//Declaración de la clase
Class("Point", {
has: {
x: {
is: "rw",
init: 0
},
y: {
is: "rw",
init: 0
}
},
methods: {
clear: function () {
this.setX(0);
this.setY(0);
}
}
})
})
// Creamos el objeto y lo usamos
var point = new PointModule.Point();
point.setX(10)
point.setY(20);
point.clear();
CSS: Posicionamiento absoluto Faux
Traducido del artículo de Eric Sol en A List Apart. Lo he leído y me ha parecido más que interesante por lo que lo he traducido entero.
Hay dos enfoques populares para el posicionamiento con CSS: float y posicionamiento absoluto (position:absolute). Ambos métodos tienen sus pros y sus contras. Mi equipo y yo hemos desarrollado un nuevo enfoque de posicionamiento que nos da lo mejor de ambos mundos. Después de un poco de experimentación y ensayo, es el momento de compartir la técnica con el resto del mundo y ver cómo podemos trabajar juntos para mejorarla. Yo la llamo "posición absoluta faux" debido a la técnica de columnas falsas (faux) que simula la presencia de una columna.
¿Por qué necesitamos otra técnica de diseño CSS?
Muchos diseños de sitio web se basan en una disposición de columnas con una cabecera y pie de página. Con diseños totalmente posicionado, es casi imposible colocar el pie de página si las columnas pueden crecer verticalmente. Con diseños
float, cambios inesperados de contenido pueden causar que columnas enteras salten de su envoltura ( "float drop"), tal y como se describe por Shaun Inman en Clearance. Esto es indeseable y difícil de controlar con Internet Explorer debido al tratamiento problemático por IE de width.Nuestro caso de uso es aún más complejo: mi equipo estaba desarrollando un generador de formularios WYSIWYG basado en web que permite al usuario arrastrar elementos a lugares arbitrarios dentro del lienzo (canvas). Teníamos que dejar que nuestros usuarios creasen atractivos formularios que no usasen posicionamiento estático y que les dejase alinear columnas cuando sea necesario.
Por ejemplo, supongamos que queremos un formulario que tenga los campos de código postal y ciudad en la misma fila porque están relacionados semánticamente. Para lograr esto, hemos intentado utilizar posicionamiento flotante inspirado por la técnica del Santo Grial. El uso de este método necesita que ajustemos el ancho, los bordes, los márgenes, y/o el relleno interior (padding) del campo código postal para ajustar el campo ciudad a una determinada posición horizontal. Pero esto era un problema porque si la anchura del campo del código postal necesitaba un ajuste, o si queríamos ajustar la cantidad de espacio en blanco entre los campos, el campo de ciudad tendría que ajustarse también. Cuanto más elementos en una página -más celdas en la malla- más tedioso se convierte este tipo de ajuste. Además, el posicionamiento es sensible al más mínimo cambio en una serie de parámetros, por lo que resulta casi imposible de controlar en caso de elementos de formulario dinámicos.
A continuación, intentamos utilizar el posicionamiento absoluto. Esto nos dio mucho más control sobre el posicionamiento de estos elementos y es robusto. Pero los elementos posicionados absolutamente no tienen altura, y eso causó que el elemento contenedor (el canvas) se comprimiese verticalmente. Esto hacía difícil posicionar contenido sin hacerlo todo posicionado absolutamente - lo cual es imposible de lograr con contenido dinámico.
Un enfoque diferente
Por último, intentamos una solución basada en encontrar la manera de calcular la compensación (offset) a la izquierda desde una posición fija, en contraposición a calcularla desde el borde derecho del elemento anterior. Lo hemos conseguido utilizando una combinación de
position: relative, left: 100% y un margin-left negativo.Nuestro método comienza por la construcción de una malla de líneas y elementos. Podemos colocar cualquier número de elementos en una línea y cualquier número de líneas en el elemento contenedor:
<div id="canvas">
<div class="line">
<div class="item" id="item1">
<div class="sap-content">contenido aquí</div>
</div>
</div>
</div>
... y así sucesivamente. Cada elemento tiene un
div sap-content extra con varios propósitos:- Evita el redraw bug en IE6,
- nos da más flexibilidad para añadir relleno interior (ver ejemplo a continuación), y
- nos permite jugar con
position:overflow(sin romper la malla).
El CSS genérico aplicado a estos elementos es el siguiente:
.line {
float: left;
width: 100%;
display: block;
position: relative;
}
.item {
position: relative;
float: left;
left: 100%;
}
Para colocar un elemento en particular, todo lo que hay que hacer es darle un
margin-left negativo y una anchura. Por ejemplo:
#item1 {
margin-left: -100%;
width: 30%;
}
Con algo más de estilo, a efectos de demostración, sería algo así:
 Ejemplo de Posicionamiento absoluto Faux en acción.
Ejemplo de Posicionamiento absoluto Faux en acción.
El CSS genérico posiciona cada elemento en el lado derecho del canvas, con el ancho de cada elemento basado en su contenido y todos los elementos flotados en el orden del código fuente HTML. El
margin-left es ahora un desplazamiento de compensación (offset) desde la parte derecha del canvas en lugar de serlo desde el elemento a su izquierda.Ventajas
Con el posicionamiento absoluto faux, podemos alinear todos los elementos a una posición predefinida en la malla (al igual que con el posicionamiento absoluto), pero los elementos todavía afectan al flujo normal (y gracias a
clear) tiene muchas de las mismas ventajas que con el flujo normal de los elementos. Cada fila de la malla siempre tendrá una altura que depende del contenido o bien tal y como se defina en el CSS, y siempre tomará hasta el 100% de la anchura, sin importar cuántas columnas se definen en la fila. Por otra parte, podemos evitar el uso de engorrosos márgenes o rellenos interiores para ajustar la cantidad de espacio en blanco entre los elementos -lo que es un plus, ya que estas técnicas casi siempre nos obligan a usar hacks específicos para IE6 para compensar el modelo de cajas del navegador.Otra ventaja de esta técnica es que mitiga gran parte de la fragilidad de los floats. Cuando el contenido de una caja flotada es más amplio que la propia caja, empuja a la siguiente caja hacia la derecha (y como consecuencia, la caja a menudo cae a la siguiente fila rompiendo el diseño). Con el posicionamiento absoluto faux, la caja de la derecha se mantiene en su lugar, no importan las condiciones. El contenido de las cajas puede solaparse (en función de otras variables tales como
overflow:hidden), pero eso es todo -y en nuestra opinión, es mejor correr el riesgo de solapamiento que arriesgarse a romper todo el esquema.Inconvenientes
El posicionamiento absoluto faux está muy inspirado por y destinado a los diseños basados en mallas y es más gratificante con diseños más complejos. Si tienes un diseño de de dos columnas de ancho fijo, esta puede no ser la técnica más apropiada.
Además, el posicionamiento absoluto faux no funciona para todas las situaciones. Si quieres alinear elementos a la izquierda, no puedes utilizar una unidad que sea diferente de la unidad utilizada para la anchura del canvas, porque no se puede calcular el desplazamiento (offset). Por ejemplo, si tienes un ancho de canvas con
width:800px y quieres un desplazamiento a la izquierda de 2em para un elemento, no es posible calcular el margen izquierdo porque no se puede saber cuántos ems caben en 800 píxeles.Y puesto que se trata de una nueva técnica que no ha sido probada por miles de usuarios, debe todavía ser considerada experimental, ya que se pueden ver resultados inesperados con la actual combinación de código HTML, CSS, y navegador.
Una cuestión pendiente: cuando un elemento más ancho que el canvas precede a otros elementos en el código fuente HTML, los elementos posteriores en la misma línea serán empujados a la derecha por una cantidad igual a la diferencia de anchura entre el primer elemento y el canvas.
Ejemplos
El primer ejemplo es un diseño líquido de tres columnas siendo las dos laterales fijas, al igual que el Santo Grial. He implementado esta disposición como una plantilla de Drupal, un popular CMS de código abierto. Pero hay algunas cosas que observar:
- Las columnas izquierda y derecha tienen anchos en píxeles. Por lo tanto, no se puede calcular el margen izquierdo para el contenido principal, porque no sabemos el ancho del canvas o el ancho de la columna de la izquierda como un porcentaje del canvas. La solución es similar al Santo Grial: posicionar el contenido principal con
margin-left: -100%ywidth: 100%y añadir el relleno interior (padding) con píxeles para garantizar el espacio necesario para las columnas. - Las columnas izquierda, principal, y derecha se muestran en el mismo nivel jerárquico, por lo que es posible necesitar algo como
z-index: 100en las columnas. - El relleno interior para las columnas izquierda y derecha se añade al
div.sap-contentextra, lo que mantiene los cálculos simples, a la vez que ofrece una gran cantidad de flexibilidad.
¡No requiere hacks!
Nuestra solución no requiere hacks y funciona con todos los navegadores modernos (Safari, Opera, Firefox, IE7), así como IE6 e incluso IE5.5/Win. No funciona en IE5/Mac, pero ya que este producto ha sido retirado, no está en nuestra lista de prioridades.
La solución también es muy estable, ya que los elementos crecen verticalmente en caso necesario, y la disposición no se rompe cuando una imagen es más ancha que el elemento, por ejemplo. El posicionamiento de los elementos es independiente del orden en el código HTML.
Estoy muy entusiasmado con este planteamiento y le veo muchas posibilidades. Siéntete libre para probar, experimentar y publicar tus comentarios.
Comprobar si el prototipo de un objeto se ha ampliado
Con esta sencilla función que propone Andrea Giammarchi en Web Reflection, es posible averiguar si el prototipo de un objeto ha sido ampliado definiendo más funciones o propiedades.
Function.prototype.prototyped = function(){
for(var i in new this)
return true;
return false;
};
alert(Array.prototyped()); // false (la clase Array no se ha tocado)
Object.prototype.each = function(){};
alert(Array.prototyped()); // true (la clase Array se ha ampliado con la función each)
16 junio, 2008
Incrustar JavaScript
John Resig hace una rápida revisión de las opciones existentes para incrustar un intérprete Javascript desde otros lenguajes (Python, Perl, PHP, Ruby, and Java). Como bien dice, a él le gusta ver Javascript como si fuese agua porque toma la forma de su contenedor y esa unión mejora su sabor.
13 junio, 2008
Hoja de referencia para MooTools 1.2
También conocidas como chuletas o cheat sheets. Via aNieto2K. Creada por Mediavrog.net.
Descargar:
PDF

12 junio, 2008
MooTools 1.2
Aunque por el número de versión pudiera parecer que se trata de una versión menor, la gente de MooTools se ha decidido tras unos meses de prueba a liberar oficialmente la versión 1.2 de la librería, con profundos cambios a nivel de estructura (deja de ser directamente compatible con la anterior 1.11, pero hay un plugin para asegurar la compatibilidad en todos los casos) y una reorganización importante de la web del proyecto.
Ver demos. Ver documentación. Descargar (La versión completa ocupa unos 60KB).
11 junio, 2008
#
Me acabo de dar cuenta de algo a lo llevaba dando vueltas en mi cabeza un tiempo. El tipado estático en los lenguajes OO (orientados a objetos) no es una solución a la complejidad del software, sino más bien un habilitador de esa complejidad. El tipado estático es como dar chicles de menta a un borracho y decirle "No conduzcas borracho. Pero si debes hacerlo y te detienen, usa los chicles".
El problema del tipado estático es que tiende a fomentar interfaces grandes y complejas como las de las frameworks, en lugar de interfaces modulares y desacopladas como las que todo el mundo desea. Lo irónico es que si tus interfaces son pequeños y simples, entonces el tipado estático te ofrece muy poco beneficio. El tipado estático funciona mejor cuando hay mucha complejidad, pero como los chicles de menta para el borracho, estamos facilitando una salida fácil con lo que sabemos que es un error en cualquier caso.
10 junio, 2008
Mascara
John Resig descubre Mascara, un conversor de código desde la nueva versión de Javascript 2 (o EcmaScript 4) a la actual. Soporta las siguientes características de la nueva versión:
- Verificación de tipos
- Clases y herencia, constructores, super inicializadores
- Miembros estáticos
- Inferencia de tipos a partir de la inicialización
- Tipos parametrizados, Map y Vector
- Tipos Unión
- Tipos estructurales
- Getters/setters
- Namespaces
- Tipos anulables
Cuando REST mató a SOAP
Leyendo un artículo en exuys.com que intenta explicar REST con unas palabras distintas a las oficiales, llego a la conclusión de que la explicación no me convence. Tampoco me gusta la de la wikipedia, pero sí la de Tomayko.com explicándole el concepto a su mujer. Mi versión es la que sigue.
REST es un estilo de programación para establecer una conexión con servidores e intercambiar información. Con REST se definen recursos conceptuales que tienen una representación y que son accesibles por medio de una cadena de texto llamada URI. Visto así puede parecer complejo, pero si cambiamos URI por URLs como http://digitta.com, cambiamos los recursos por páginas web y cambiamos su representación por HTML o SWF, todo empieza a tener un aire más familiar.
Cuando apareció SOAP, un protocolo complejo por el cuál un programa solicita información a un servidor, se tuvo en cuenta todo el conocimiento que hasta el momento se había utilizado, por lo que se pensó en componentes especiales tanto en el cliente como en el servidor. Pero eso añadía una capa más de complejidad que REST ha demostrado totalmente innecesaria:
Con REST, las peticiones se realizan a servidores web. Los verbos GET, POST, PUT o DELETE que ya pertenecían al protocolo HTTP desde sus inicios, se adaptan como un guante a las cuatro acciones estándar CRUD (Create, Read, Update, Delete). El que usamos habitualmente cuando introducimos una dirección en el navegador y pulsamos intro es GET, que se adapta perfectamente a la lectura/visualización de un recurso.
La enorme ventaja de utilizar REST es que pueden probarse en el navegador introduciendo a mano (o a través de formularios) las peticiones al servidor e inspeccionar el resultado de la misma forma con la que visitaríamos una página web. Todas las piezas estaban ya ahí y sólo era cuestión de usarlas de forma adecuada, con la ventaja añadida de que todas las características de HTTP como balanceo de carga, cachés, proxys, compresión de datos transmitidos, etc. están automáticamente disponibles.
Para comprobar la tremenda sencillez del concepto REST y la razón por la que se está imponiendo, vale una simple llamada a la API de tinyurl.com (un servicio web gratuito para acortar direcciones largas por otra equivalente mucho más corta):
http://tinyurl.com/api-create.php?url=http://digitta.com
A primera vista es una simple dirección web, pero cuyo resultado...
http://tinyurl.com/4can6t
...no está pensado para ser visualizado por un humano sino consumido por un programa. El servicio no distingue ambos usos y poder ver el resultado en el navegador permite comprender rápidamente el funcionamiento del servicio o probarlo para detectar errores sin necesidad de pelearse con componentes y con el código para prepararlos.
08 junio, 2008
La arquitectura de LinkedIn

Me resulta muy interesante conocer cómo los sitios más concurridos de internet se las apañan para preparar la infraestructura necesaria para poder tratar con todas esas miles de peticiones por segundo. No todo es cuestión de hardware, muchas veces, ajustar algunos parámetros y darle vueltas a las cosas con una dosis de ingenio es suficiente para alcanzar los resultados que ofrecen productos hardware muy caros.
En Cookies are for Closers tienen un par de enlaces a las presentaciones que empleados de LinkedIn dieron en JavaOne 2008. El artículo resume las claves de la arquitectura a la que han llegado a base de prueba y error y continuas pequeñas optimizaciones.
La profesionalización de los lenguajes interpretados
Via Simon Willison, frase de Joe Gregorio:
Hubo un tiempo en que podías unir un parseador en lex y Yacc, pegarle un simple VM y lanzarlo a la pared y tendrías un nuevo lenguaje de scripting. Esos días están llegando a su fin y en pocos años (si no meses) no podrás mantenerte actualizado a menos que esté basado en registros e implemente direct threading, Garbage Collection generacional, optimizaciones de ventana, trace-folding, caché en línea de tipos deducidos ¿inferenced tipo de línea de caché, etc.
07 junio, 2008
280slides.com
280slides es una aplicación web para crear presentaciones completas que pueden bajarse como archivos de PowerPoint, enviarse a SlideShare o ser visualizadas directamente en su web. La gracia está en que utiliza un clon de Objective-C escrito en 13KB de JavaScript y parece que les ha funcionado muy bien. Entrevista en Ajaxian con los autores.

06 junio, 2008
FlickrTrans 1.0
Harto de buscar una extensión para Firefox que funcionase igual de bien que ImageShack right-click pero para Flickr, me he puesto manos a la obra.
En realidad había encontrado una extensión que realizaba casi todo el trabajo: Uploadr for Flickr 1.0 de Bill Conan. Pero dicha extensión aprovecha el servicio de Flickr en la URL http://www.flickr.com/tools/sendto.gne?url=URL_DE_LA_IMAGEN_A_CARGAR, el cual, una vez cargada (transloading) la imagen, no da ninguna opción para acceder a la galería del usuario. Así que, ni corto ni perezoso, me baje el XPI y me puse a trastear.
Mi experiencia con extensiones de Firefox es casi nula. Sabia que los XPI eran archivos ZIP renombrados y que todo estaba a la vista y basado en XUL (el lenguaje de marcado de interfícies de usuario de Mozilla). En realidad, la extensión no es muy complicada. Casi todo el trabajo se realiza en un HTML estático con un poco de Javascript que controla los pasos de la carga. Este es el código actual de dicho archivo:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
<meta http-equiv="content-type" content="text/html; charset=UTF-8" />
<meta http-equiv="content-style-type" content="text/css" />
<meta http-equiv="content-script-type" content="text/javascript" />
<!-- link rel="stylesheet" href="default.css" type="text/css" media="screen, print" /-->
<title>Transloading to Flickr</title>
</head>
<body onload="loaded()">
<iframe id="ifr" name="ifr" src="about:blank" width=0 height=0 style="display:none"></iframe>
<form id="form" action="http://www.flickr.com/tools/sendto.gne" method="get" target="ifr">
<input type="hidden" name="url" id="url" value="" />
</form>
<div style="margin: 100px auto 0 auto; text-align:center; width:100%;">
<img src="chrome://flickrtrans/content/logo.jpg" /><br/>
<h1> Transloading... <span id="h1"></span></h1>
<img src="chrome://flickrtrans/content/flickr.gif" align="absmiddle" /> <a href="http://digitta.com/">FlickrTrans 1.0</a>
by <img src="chrome://flickrtrans/content/digitta.png" align="absmiddle" /> <a href="http://digitta.com">digitta.com</a>.
<br/><br/>
<img src="chrome://flickrtrans/content/loading.gif" />
<br/>
<img src="chrome://flickrtrans/content/favicon.png" id="target" style="border:1px solid black; max-width: 150px;" />
</div>
<script>
function loaded() {
url=location.href.substr(location.href.indexOf('=')+1);
document.getElementById('url').value= decodeURIComponent(url);
document.getElementById('target').src= decodeURIComponent(url);
document.getElementById('ifr').onload= frameloaded1;
document.getElementById('url').form.submit();
document.getElementById('h1').innerHTML= '1/3';
}
function frameloaded1() {
if(~document.getElementById('ifr').contentDocument.body.innerHTML.indexOf('password')) {
// not authenticated
alert('You are not logged in Flickr. Please log in there before using FlickrTrans');
top.location.href=document.getElementById('ifr').contentDocument.location.href;
return false;
}
document.getElementById('ifr').onload= frameloaded2;
window.flickrname= document.getElementById('ifr').contentDocument.getElementsByTagName('b')[1].innerHTML;
createCookie('flickrname',window.flickrname,60);
document.getElementById('ifr').contentDocument.forms[0].submit();
document.getElementById('h1').innerHTML= '2/3';
}
function frameloaded2() {
id=readCookie('flickrid') || window.flickrId;
if (!id) return getFlickrId();
top.location.href='http://www.flickr.com/photos/'+id;
document.getElementById('h1').innerHTML= '3/3';
}
function callServer(url) {
var head= document.getElementsByTagName("head").item(0);
var script= document.createElement("script");
script.src= url;
script.type= "text/javascript";
void (head.appendChild(script));
}
function getFlickrId() {
callServer('http://api.flickr.com/services/rest/?method=flickr.people.findByUsername&format=json&api_key=d7c94440fdce1b53a39b071f471b74a0&username='+window.flickrname);
return false;
}
function jsonFlickrApi(data) {
id= data.user.id;
window.flickrId=id;
createCookie('flickrid',id,60);
frameloaded2();
}
// from http://www.quirksmode.org/js/cookies.html
function createCookie(name,value,days) {
if (days) {
var date = new Date();
date.setTime(date.getTime()+(days*24*60*60*1000));
var expires = "; expires="+date.toGMTString();
}
else var expires = "";
document.cookie = name+"="+value+expires+"; path=/";
}
function readCookie(name) {
var nameEQ = name + "=";
var ca = document.cookie.split(';');
for(var i=0;i < ca.length;i++) {
var c = ca[i];
while (c.charAt(0)==' ') c = c.substring(1,c.length);
if (c.indexOf(nameEQ) == 0) return c.substring(nameEQ.length,c.length);
}
return null;
}
function eraseCookie(name) {
createCookie(name,"",-1);
}
</script>
</body>
</html>
Existen un iframe oculto y vacío y un formulario con un campo también oculto. Al cargarse la página, se llama a la función loaded que obtiene el parámetro url de window.location, lo carga en el campo oculto del formulario y lo envía al servicio de Flickr antes mencionado cargando el resultado en el iframe. Cuando se acabe de cargar, se llama a
frameloaded1 (soy genial para los nombres) que comprueba si está solicitando la contraseña y por tanto el usuario no está autenticado en Flickr en cuyo se redirige a la página de autenticación. Se lee el contenido de la respuesta, incluyendo el nombre de usuario que aparece en la página y un nuevo formulario que es la confirmación de la carga y que se realiza automáticamente desde Javascript. Al cargar de nuevo la respuesta, si no se tiene el id de Flickr (se guarda en una cookie la primera vez), llama a la función de la API de Flickr flickr.people.findByUsername para obtener el id a partir del nombre de usuario. Con el id ya es posible redirigir a la página de la galería del usuario, que tiene la forma
http://www.flickr.com/photos/id.


Esta es la página de la extensión. La extensión se puede instalar desde allí. Addendum: Debido a que todavía se encuentra en fase de preview, he colgado el XPI también de aquí.

Cargar con Ajax más contenido al llegar abajo
Una de las mejoras más evidentes que Ajax ha traido a muchas aplicaciones web es la de cargar contenido extra al vuelo (sin necesidad de recargar la página) cuando se alcanza el límite inferior del contenido actual: ver ejemplo.
La ventaja de este método es evidente, al evitar la necesidad de paginar el contenido y esperar a la carga de una nueva página con contenido nuevo. De hecho, si se hace bien, es posible solicitar el siguiente bloque de datos antes de que se alcance el final, por lo que normalmente el usuario no tendría que esperar nunca a que le lleguen datos ya que siempre tendría nuevos disponibles.
En Sentido Web (donde ya lo implementaron sin librerías) se hacen eco de este artículo en el que ofrecen una implementación de esa técnica pero basada en la librería jQuery de John Resig.

La ventaja de este método es evidente, al evitar la necesidad de paginar el contenido y esperar a la carga de una nueva página con contenido nuevo. De hecho, si se hace bien, es posible solicitar el siguiente bloque de datos antes de que se alcance el final, por lo que normalmente el usuario no tendría que esperar nunca a que le lleguen datos ya que siempre tendría nuevos disponibles.
En Sentido Web (donde ya lo implementaron sin librerías) se hacen eco de este artículo en el que ofrecen una implementación de esa técnica pero basada en la librería jQuery de John Resig.
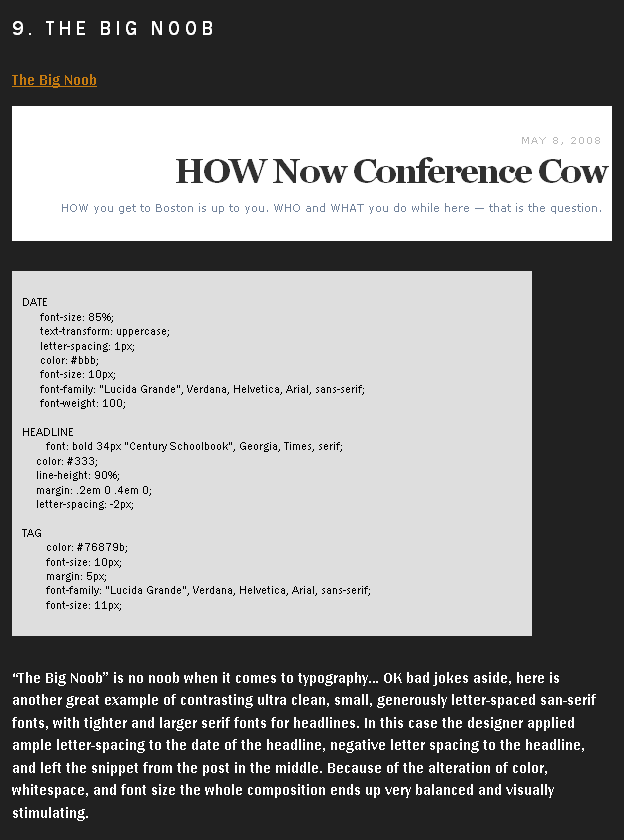
Un par de "trucos"
Web Reflection. Son viejos, pero siempre conviene recordarlos.
Es habitual usar Math.floor para redondear un cociente...
var centerWidth = Math.floor((something + someelse - someother) / 2);
>> :
var centerWidth = (something + someelse - someother)>>1;
if(myWord.indexOf(myChar) >= 0) ...
if(myWord.indexOf(myChar) !== -1) ...
if(~myWord.indexOf(myChar)) ...
~ es un operador disponible en varios lenguajes que convierte un número entre 0 y N en otro entre -1 y -(N+1), por lo que si se le aplica al resultado de indexOf devolverá 0 si no lo encuentra o un valor negativo en caso contrario.
05 junio, 2008
El diablo está en los detalles
Ignore Details Early On (by 37signals):
El éxito y la satisfacción están en los detalles. Pero el éxito no es lo único que encontrarás en los detalles. También están el estancamiento, el desacuerdo, las reuniones y los retrasos. Todo eso destroza la moral y rebaja las posibilidades de éxito. [...]
04 junio, 2008
Cotizaciones en tiempo real con Comet
En Comet Daily se hacen eco de la noticia, desde ya Google Finance refleja la cotización de los valores bursátiles en tiempo real gracias a la tecnología Comet: actualizar una página web en el navegador por iniciativa del servidor y gracias a una conexión persistente entre ambos.

03 junio, 2008
Conseguir con PHP el comportamiento de prototipos de Javascript
Web Reflection: Interesante artículo en el que explican cómo gracias a las extensiones RunKit y ClassKit de la librería PECL se permite escribir código como el siguiente:
// basic class
class Demo {
public static $prototype;
}
// prototype assignment, with optional methods
Demo::$prototype = new prototype(
'Demo',
array(
'set_name' => array('$name', '$this->name = $name;'),
'get_name' => array('return $this->name;')
)
);
// a generic instance
$demo = new Demo();
$demo->set_name('Andrea Giammarchi');
echo $demo->get_name(); // Andrea Giammarchi
// add more prototypes
Demo::$prototype->set_age = array('$age', '$this->age = $age;');
Demo::$prototype->get_info = array('return $this->name." is ".$this->age." years old";');
$demo->set_age(30);
echo '
', $demo->get_info();
// Andrea Giammarchi is 30 years old
?>
oohEmbed.com
oohEmbed.com es un proveedor oEmbed de código HTML para insertar a partir de varios sitios web. Habría que recordar que oEmbed es un formato para permitir una representación insertable (embedded) de una URL de terceros como Youtube o Flickr que permite obtener información sobre el objeto representado sin tener que parsear el recurso directamente. Por ejemplo, la siguiente petición:
Dará como respuesta:
http://oohembed.com/oohembed/?url=http://www.amazon.com/Myths-Innovation-Scott-Berkun/dp/0596527055/
Dará como respuesta:
{
"asin": "0596527055",
"title": "The Myths of Innovation",
"url": "http://ecx.images-amazon.com/images/I/31%2BfVjL2nqL.jpg",
"thumbnail_width": "48",
"height": "500",
"width": "317",
"version": "1.0",
"author_name": "Scott Berkun",
"provider_name": "Amazon Product Image",
"thumbnail_url": "http://ecx.images-amazon.com/images/I/31%2BfVjL2nqL._SL75_.jpg",
"type": "photo",
"thumbnail_height": "75",
"author_url": "http://www.amazon.com/gp/redirect.html%3FASIN=0596527055%26location=/Myths-Innovation-Scott-Berkun/dp/0596527055"
}PHP Benchmark
The PHP Benchmark fue construido como una forma de abrir los ojos de la gente al hecho de que no todos los segmentos de código PHP se ejecutan a la misma velocidad. Podrías sorprenderte de los resultados que esta página genera, pero son correctos. Ejemplo:
Cuál es la mejor forma de recorrer un hash array?
$size = sizeOf($key);
for ($i=0; $i<$size; $i++) $tmp[] = $aHash[$key[$i]];
Dado un Hash array con 100 elementos, claves de 24 bytes y 10k de datos por cada entrada...
+ 618 %
foreach($aHash as $val); Total time: 7 µs
+ 171 %
while(list(,$val) = each($aHash));Total time: 7 µs
+ 765 %
foreach($aHash as $key => $val);Total time: 31 µs
+ 100 %
while(list($key,$val) = each($aHash));Total time: 4 µs
+ 1506 %
foreach($aHash as $key=>$val) $tmp[] = $aHash[$key];Total time: 61 µs
+ 100 %
while(list($key) = each($aHash)) $tmp[] = $aHash[$key];Total time: 4 µs
+ 2147 %
Get key-/ value-array: foreach($aHash as $key[]=>$val[]);Total time: 87 µs
+ 1976 %
Get key-/ value-array: array_keys() / array_values()Total time: 80 µs
+1631535 %
$key = array_keys($aHash);$size = sizeOf($key);
for ($i=0; $i<$size; $i++) $tmp[] = $aHash[$key[$i]];
Total time: 66128 µs
Lenguajes dinámicos y SquirrelFish
Hace unos días, Steve Yegge de google publicó una transcripción de su presentación llamada "los lenguajes dinámicos contraatacan". En ella, ponía de manifiesto como nos formamos en un entorno de lenguajes compilados (como el C) y creamos una cierta predisposición a considerarlos idóneos para cualquier trabajo. Dentro de ese posicionamiento casi religioso (tipo dogma), se acusa a los lenguajes dinámicos de resultar extremadamente lentos o de que no se crean aplicaciones enormes con ellos y alguna razón debe haber. Lo cierto es que la tecnología de los compiladores se ha beneficiado de múltiples optimizaciones gracias a la fuerte investigación que ha recibido durante todos estos años.
Sin embargo, gracias al auge de lenguajes como Python, Ruby o ahora Javascript, todos ellos interpretados, están apareciendo muchas propuestas que, poco a poco, están acercando los lenguajes dinámicos a los de toda la vida. Los programadores que suelen probar un proyecto con alguno de estos lenguajes, suelen quedar sorprendidos por la alta productividad que resulta de no tener que compilar el código y de no depender de otras características como el tipado rígido. Más que nada porque han albergado y defendido hasta la saciedad el carácter infantil de dichos lenguajes.
La presentación de Yegge identifica con bastante claridad los tópicos, casi todos falsos, en los que se basan los partidarios de los lenguajes estáticos. Hay un tremendo margen de mejora, como evidencian proyectos como el nuevo SquirrelFish, un nuevo intérprete de Javascript para el navegador WebKit (Apple Safari) que casi duplica el rendimiento del actual pese a que no se le consideraba lento.
Precisamente para acallar algunas críticas respecto a la velocidad, el equipo responsable de la nueva versión de EcmaScript (Javascript), lenguaje que no recibía actualización desde hace años, ha incorporado multitud de nuevas características. En un futuro artículo trataré de analizarlas, pero considero que muchas de ellas no son más que intentos de copiar a los lenguajes estáticos para intentar atraer a sus programadores. Adobe mismo ha criticado muchas de esas nuevas características, por no haberse probado lo suficiente, resultar complicadas de implementar y existir múltiples dudas sobre su idoneidad. Personalmente creo que la mayor parte de los cambios no resultan adecuados y traicionan en gran medida la gracia y la ortogonalidad del lenguaje.

02 junio, 2008
Cambio de paradigma
Traduzco el artículo Paradigm Shift de plok (Jan Lehnardt):
Las bases de datos que usamos hoy se diseñaron hace 20 o 30 años. Saltemos al DeLorean y visitemos los 70.
Los ordenadores eran máquinas masivas. Eran muy caras y sólo había unas pocas, por lo que su disponibilidad era escasa. Tampoco eran rápidas (cualquier mando a distancia de hoy día es más rápido) y se usaban principalmente en un entorno científico.
Un escenario: Un científico investiga algo (ellos hacen esas cosas) y llego al punto de obtener tablas y tablas de datos y ahora quiere hacer algo de análisis. Él solicita un turno de tiempo para una de esas máquinas masivas, espera unas pocas semanas y entonces puede enviar los datos e instrucciones a ejecutar en esa máquina. Si el conjunto de datos es demasiado grande o las instrucciones demasiado chapuceras y los cálculos llevan más tiempo del asignado al turno... bueno, lo has adivinado: de vuelta a la mesa de dibujo.
Las bases de datos relacionales se diseñaron en ese mundo. Requieren enormes cantidades de trabajo en primer lugar (diseño de esquema, normalización de datos, diseño de consultas, optimización de rendimiento) para permitir que consultas simples se ejecuten a la máxima velocidad. Y esto tenía sentido. En aquella época.
El mundo de la informática y los patrones de uso de hoy son fundamentalmente diferentes. Miles de usuarios actualizan su estado en Twitter y Facebook este mismo minuto, en paralelo. Ellos lo hacen desde todas las partes del mundo sin interrupción; internet siempre está despierto.
El hardware ha cambiado también. Viniendo de enormes máquinas de una sola CPU, ahora tenemos enormes cantidades de cajas de artículo con configuraciones multi-núcleo y multi-cpu. De nuevo, hay una diferencia fundamental.
Lo que me resulta pasmoso es que aún usemos bases de datos que fueron utilizadas para unos casos de uso totalmente diferentes. Lo que resulta incluso más asombroso es que estas bases de datos están preparadas para el trabajo. Hay un montón de trabajo invertido, pero al final, todas los páginas web de alto tráfico utilizan alguna RDBMS. Y estoy muy impresionado con el hecho de que estas RDBMS realmente funcionen en este particular entorno hostil (para ellas).
Ahora esto no es enteramente cierto: "Un montón de trabajo invertido" en este caso significa romper con las leyes de diseño fundamentales del almacenamiento de datos relacionales: Desnormalización, redundancia, consistencia eventual. El resultado es escalabilidad: Hacer que un servicio se ejecute sobre suficiente hardware de forma que todos los usuarios puedan enviar sus mensajes, actualizar sus perfiles y subir sus vídeos.
¿Cómo puedo escribir ocho párrafos sin mencionar aquí CouchDB? Mencionaré una pequeña anécdota aunque es más sobre Erlang que sobre CouchDB: En una actuación de consultoría teníamos una hermosa imposición para ejecutar una RDBMS y con años de análisis, optimización y cacheo hemos conseguido un par de centenares de peticiones concurrentes por cada servidor. Esto es suficiente para la aplicación y, probablemente, suficiente para crecer los próximos años.
Haciendo una simple prueba de rendimiento concurrente se revela que puedo servir unas 1000 peticiones de lectura concurrente con CouchDB desde mi Mac Mini (el límite aquí es realmente la entrada/salida del disco, ya que CouchDB no realiza ningún tipo de cacheo interno por el momento (aunque lo hará pronto, no te preocupes :) Las lecturas son lo suficientemente aleatorias como para eliminar las cachés de disco y del sistema de archivos).
Pero esta no es una comparación justa, las peticiones no realizan los mismos cálculos por lo que no pueden ser comparadas. Pero tampoco son justas de la otra forma: CouchDB y los tests no están optimizados mientras que la otra instalación ha llevado unos cuantos años en realizarse.
Pero lo que hace es ilustrar perfectamente que optimizar una sola consulta en una base de datos relacional sólo te lleva a una mejora específica, y abrazar el mundo de la computación de hoy en día lleva a resultados más satisfactorios.
Y no, no estoy diciendo que los RDBMS sean una idea estúpida o vayan a desaparecer pronto.
Suscribirse a:
Entradas (Atom)
 Contactar
Contactar